从 C++11 开始,标准库中对于关联容器进行了扩充,提供了基于 哈希表 实现的关联容器。哈希表会占用比存储的元素更多的内存,换来的是均摊 \(O(1)\) 的性能。
哈希表
之前有过对于哈希表的 详细介绍,所以本文更侧重于实现
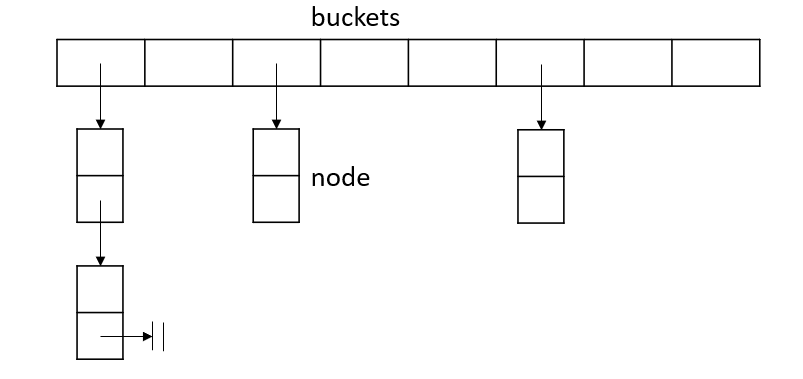
解决冲突的策略有很多,标准库中选择使用 分离链接法,即冲突的元素都会被放在一个位置,用一个链表存储。
数据结构
这里将哈希表中每个元素称为一个桶(bucket),每个被插入的元素利用哈希函数映射到对应的桶,然后作为一个结点放入其中。
1
2
3
4
5
6
7
8
template<class Value>
struct _hash_table_node
{
Value val;
_hash_table_node* next;
_hash_table_node(Value v) :val(v), next(nullptr) {}
};
质数选取
哈希表为求得更好的性能,桶数量需要是质数,为了能快速得到质数,预先定义了一批。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static const int _stl_num_primes = 28;
static const size_t _stl_prime_list[_stl_num_primes] = {
53ul, 97ul, 193ul, 389ul,
769ul, 1543ul, 3079ul, 6151ul, 12289ul,
24593ul, 49157ul, 98317ul, 196613ul, 393241ul,
786433ul, 1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul, 50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul, 1610612741ul, 3221225473ul, 4294967291ul
};
inline size_t max_bucket_count() {
return _stl_prime_list[_stl_num_primes - 1];
}
inline size_t _stl_next_prime(size_t n) {
const size_t* first = _stl_prime_list;
const size_t* last = _stl_prime_list + _stl_num_primes;
// lower_bound 用于找到 [first,last) 中第一个不小于 n 的元素
const size_t* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
声明
为了能让桶数量动态增长,所以用 vector 作为桶的容器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
template<class Value, class Key, class HashFunc, class ExtractKey,
class EqualKey, class Alloc = allocator<Value>>
class hash_table
{
public:
using hasher = HashFunc;
using key_equal = EqualKey;
using size_type = size_t;
using value_type = Value;
using key_type = Key;
using iterator = _hash_table_iterator<Value, Key, HashFunc,
ExtractKey, EqualKey, Alloc>;
private:
hasher hash_;
key_equal equal_;
ExtractKey get_key_;
std::vector<node*> buckets;
size_type num_elements;
node_allocator alloc_;
};
模板参数反映了整个哈希表中最核心的内容。
Value:值类型。值得注意的是这并非是键值对概念中的值,而是 node 中真正存放的类型,稍后介绍 map 时可以看到区别。Key:键类型。HashFunc:哈希函数。用于映射元素到桶,标准库中已有定义。ExtractKey:从值中取出键的方法,稍后可以看到具体的作用。EqualKey:判断键相同的方法。Alloc:内存分配器。
内部除了 STL 容器常见的成员类型声明,数据成员都是模板参数所对应的实例。
迭代器
迭代器是一个容器不可或缺的一部分,但是哈希表中元素会被映射到不同的桶中,意味着存储是无序的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
template<class Value, class Key, class HashFunc,
class ExtractKey, class EqualKey, class Alloc>
struct _hash_table_iterator
{
using node = _hash_table_node<Value>;
using hashtable = hash_table<Value, Key, HashFunc,
ExtractKey, EqualKey, Alloc>;
using iterator = _hash_table_iterator<Value, Key, HashFunc,
ExtractKey, EqualKey, Alloc>;
using iterator_category = forward_iterator_tag;
using value_type = Value;
using difference_type = ptrdiff_t;
using size_type = size_t;
using reference = value_type & ;
using pointer = value_type * ;
node* cur;
hashtable* ht;
_hash_table_iterator(node* nodeptr, hashtable* htptr)
:cur(nodeptr), ht(htptr) {}
reference operator*() const { return cur->val; }
pointer operator->() const { return &(operator*()); }
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }
};
迭代器中常见的成员类型声明,这里迭代器是单向的,只能向前移动,所以 iterator_category 声明为 forward_iterator_tag。也正因如此,迭代器实现的关键在于自增操作符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
iterator& operator++() {
node* old = cur;
//用 next 指针获得下一个元素
cur = cur->next;
if (cur == nullptr) {
//如果到达了桶底,就去下一个有元素的桶
cur = ht->next_bkt(old->val);
}
return *this;
}
iterator operator++(int) {
iterator tmp = *this;
++*this;
return tmp;
}
函数实现
元素映射
哈希表最为核心的就是哈希函数,用以决定元素会被放入哪里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// n 代表桶的数量
size_type bkt_num(const value_type& obj, size_t n) const
{
return bkt_num_key(get_key_(obj), n);
}
size_type bkt_num(const value_type& obj) const
{
return bkt_num_key(get_key_(obj));
}
size_type bkt_num_key(const key_type& key) const
{
return bkt_num_key(key, buckets.size());
}
size_type bkt_num_key(const key_type& key, size_t n) const
{
return hash_(key) % n;
}
总共分为四个版本,无论提供键还是值,提供桶数量与否都能映射,最终都会落到第四个版本调用哈希函数上。
内存管理
buckets 是一个存储 node* 的容器,且其自身有完善的构造和析构函数,对其内存不必有太多考虑。所以此处内存管理的核心在于 node,利用 allocator 的分配(释放)内存和构造(析构)。
1
2
3
4
5
6
7
8
9
10
11
node* new_node(const value_type& obj) {
node* n = node_allocator::allocate(1); //分配内存
n->next = nullptr;
allocator_traits<node_allocator>::construct(alloc_, n, obj); //构造
return n;
}
void delete_node(node* n) {
allocator_traits<node_allocator>::destroy(alloc_, n); //析构
node_allocator::deallocate(n); //释放内存
}
vector 一般容量大小是其内部自行指定的,可是此处我们要求它为质数,所以要显示的调用相对应的函数。
1
2
3
4
5
6
void initialize_buckets(size_type n) {
//保留大于 n 的质数大小的空间
buckets.reserve(next_size(n));
//以空指针填充
buckets.insert(buckets.end(), buckets.capacity(), nullptr);
}
这样就能拥有一个完善的构造函数。
1
2
3
4
5
hash_table(size_type n, const HashFunc& func, const EqualKey& eql)
:hash_(func), equal_(eql), get_key_(ExtractKey()),
num_elements(0), alloc_() {
initialize_buckets(n);
}
插入元素
插入的元素是否可重复是可选的,所以与关联容器一样提供了两个版本 insert_unique 和 insert_equal。
对于插入操作,分为两个步骤,首先判断是否需要扩充表大小,之后再将元素插入。
1
2
3
4
5
6
std::pair<iterator, bool> insert_unique(const value_type& val) {
//扩充大小
resize(num_elements + 1);
//实施插入
return insert_unique_aux(val);
}
resize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void resize(size_type num_elements_hint) {
const size_type old_n = buckets.size();
// 这里 resize 权衡的是元素数量与桶数量之间大小关系
if (num_elements_hint > old_n) {
const size_type n = next_size(num_elements_hint);
if (n > old_n) {
//构造一个新的 vector 作为新的 buckets
std::vector<node*> tmp(n, nullptr);
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket];
while (first != nullptr) {
size_type new_bucket = bkt_num(first->val, n);
//将元素移动到 tmp 中
buckets[bucket] = first->next;
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
first = buckets[bucket];
}
}
// 与新的交换,tmp 就会成为旧的 buckets,随着函数结束析构
buckets.swap(tmp);
}
}
}
这里 resize 是 SGI STL 中的实现,发生的条件其实并没有标准。如果无需扩充函数会直接返回,所以在插入操作中只要调用就无需关心空间问题。
insert_unique
不可重复的版本会返回一个 pair,iterator 指向了插入的元素(即使元素本身就存在),bool 表明是否是新元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
std::pair<iterator, bool> insert_unique_aux(const value_type& val) {
const size_type n = bkt_num(val);
node* first = buckets[n];
for (node* cur = first; cur; cur = cur->next) {
if (equal_(get_key_(cur->val),get_key_(val))) {
//发现存在键值相同的则返回
return std::pair<iterator, bool>(iterator(cur, this), false);
}
}
//插入新节点
node* tmp = new_node(val);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return std::pair<iterator, bool>(iterator(tmp, this), true);
}
insert_equal
允许键重复的实现与不允许的类似,唯一的差别在于发现相同的时候立即插入而非返回 false,且始终都会返回插入的元素迭代器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
std::pair<iterator, bool> insert_equal_aux(const value_type& val) {
const size_type n = bkt_num(val);
node* first = buckets[n];
for (node* cur = first; cur; cur = cur->next) {
if (equals(get_key(cur->val), get_key_(val))) {
//发现存在键值相同的则立即插入
node* tmp = new_node(val);
tmp->next = cur->next;
cur->next = tmp;
++num_elements;
return iterator(tmp, this);
}
}
node* tmp = new_node(val);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return iterator(tmp, this);
}
unordered_set
在有了完善的 hash table 实现的基础上,设计 set 只是转调用 hash table 的功能而已。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
template<class Key, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>, class Allocator = allocator<Key>>
class unordered_set
{
private:
using hashtable = hash_table<Key, Key, Hash,
identity<Key>, KeyEqual, Allocator>;
public:
using key_type = typename hashtable::key_type;
using value_type = typename hashtable::value_type;
using hasher = typename hashtable::hasher;
using key_equal = typename hashtable::key_equal;
using size_type = typename hashtable::size_type;
using iterator = typename hashtable::iterator;
unordered_set() :ht(100, hasher(), key_equal()) {}
explicit unordered_set(size_type n) :ht(n, hasher(), key_equal()) {}
size_type size() const { return ht.size(); }
bool empty() const { return ht.empty(); }
iterator begin() const { return ht.begin(); }
iterator end() { return ht.end(); }
std::pair<iterator, bool> insert(const value_type& val) {
return ht.insert_unique(val);
}
iterator find(const value_type& val) { return ht.find(val); }
private:
hashtable ht;
};
identity
可以说这个实现并没有什么亮点,唯一值得注意的是 hashtable 的声明:
1
using hashtable = hash_table<Key, Key, Hash, identity<Key>, KeyEqual, Alloc>;
这里 identity<Key> 是什么?
之前提到过,这个参数是 ExtractKey,是用来将值转换为键的方法。那么对于 set 来说,键就是值,那么转换后就是将值返回。
1
2
3
4
5
6
7
template<class T>
struct identity
{
constexpr T&& operator()(T&& t) const noexcept {
return std::forward<T>(t);
}
};
这里重载了 () 操作符,使得有了类似函数的调用方法,返回值就是将传入的返回。
unordered_map
可以说对于 hashtable 的调用与 unordered_set 如出一辙,更多的修改仍在于对 hashtable 的声明上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
template<class Key, class T, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>, class Allocator = allocator<Key>>
class unordered_map
{
private:
using hashtable = hash_table<std::pair<Key, T>, Key, Hash,
select1st<Key, T>, KeyEqual, Allocator>;
public:
using key_type = typename hashtable::key_type;
using value_type = typename hashtable::value_type;
using hasher = typename hashtable::hasher;
using key_equal = typename hashtable::key_equal;
using size_type = typename hashtable::size_type;
using iterator = typename hashtable::iterator;
unordered_map() :ht(100, hasher(), key_equal()) {}
explicit unordered_map(size_type n) :ht(n, hasher(), key_equal()) {}
size_type size() const { return ht.size(); }
bool empty() const { return ht.empty(); }
iterator begin() const { return ht.begin(); }
iterator end() { return ht.end(); }
std::pair<iterator, bool> insert(const value_type& val) {
return ht.insert_unique(val);
}
iterator find(const Key& val) { return ht.find_by_key(val); }
private:
hashtable ht;
};
让我们再来仔细看一下这条成员类型。
1
2
using hashtable = hash_table<std::pair<Key, T>, Key, Hash,
select1st<Key, T>, KeyEqual, Allocator>;
这里 Value 用了 std::pair<Key, T>,而并非简单的 Value。之前有提到,这个模板参数是 node 存储的数据类型,如果单单存储一个 Value,那么当我用 Key 映射到对应的桶中时就会找不到所对应的元素。这里哈希表用的是分离链接法,也就是说所有有冲突的都会存放在其中,那么就必须有一个 Key 随着 Value 一起存储以区分。同时,如果在 hashtable 中只需要模板参数提供 Key 和 Value 的原始类型,然后内部直接用 pair 存储,这样对于 set 的实现是一种负担,所以导致了现在 hashtable 必须提供内部存储的类型。不过这些细节在使用 unordered_map 的时候理应都被封装起来,不必做太多考虑。
select1st
在这里 ExtractKey 用了一个叫 select1st 的方法。因为我们存储的类型的一个 pair<Key, Value>,从中取出键的方法就是取出第一个元素,即该方法的名称含义。
1
2
3
4
5
6
7
template<class T1,class T2>
struct select1st
{
constexpr T1 operator()(std::pair<T1, T2> t) const noexcept {
return t.first;
}
};